AWS MSK Disaster Recovery Setup

AWS MSK (Managed Service Kafka) is a fully managed service that makes it easy to build and run applications to process streaming data using Apache Kafka, an open-source platform for building real-time streaming data pipelines.
AWS MSK Connector is a feature of AWS MSK that makes it easy to stream data to and from your Kafka clusters using fully managed connectors built for Kafka Connect, an open-source framework for connecting Kafka clusters with external systems such as databases, search indexes, and file systems.
We have assisted several customers facing production disruptions while running MSK clusters in the outage-prone region US Northern Virginia (us-east-1), and during our discussions we are often asked how best to use MSK during such outages. The two commonly solutions suggested are:
1. Keep a hot Disaster Recovery (DR) MSK cluster always running in a DR region.
2. Launch a new cluster when needed in a DR region despite the ~30 minutes of downtime this brings.
Solution one is very expensive and should be budgeted into the infrastructure cost if selected. It is recommended only if the business operational loss due to MSK cluster downtime exceeds the high cost of a 24/7 duplicate infrastructure setup in another region.
Option number two, while substantially more cost effective, often has a 30 minutes downtime associated due to the time it takes AWS to provision a new MSK cluster.
Regardless of the strategy chosen, once a cluster is available we will need the latest Kafka topic data for DR cluster or newly launched cluster. This is where the AWS MSK connector comes in handy. The general approach to take is to back up the Kafka topic data to an S3 bucket, then restore it to the replacement cluster. Shown below is a figure summarizing the detailed approach I will describe in this blog post wherein we will be leveraging Confluent Amazon S3 Sink Connector in order to move MSK topic data to an S3 bucket.

Prerequisite:
1. Two S3 Buckets, one in the same region as the current MSK Cluster, and the other in the DR region
2. S3 VPC Gateway Endpoint
3. Replication between the two S3 buckets
4. Confluent Amazon S3 Sink Connector Zip File
5. AWS CloudWatch Log Group to monitor AWS MSK connector logs
6. Kafka Connector Role with S3 policy described below
Step 1: Create S3 Buckets
Create two separate S3 buckets, one in the production region and another one in the DR region. I am using US N. Virginia (us-east-1) as the production region and US Oregon (us-west-2) as the DR region.

Step 2: Launch MSK Cluster
Launch a new MSK cluster (many times you will always have a running MSK cluster so you can skip this step)
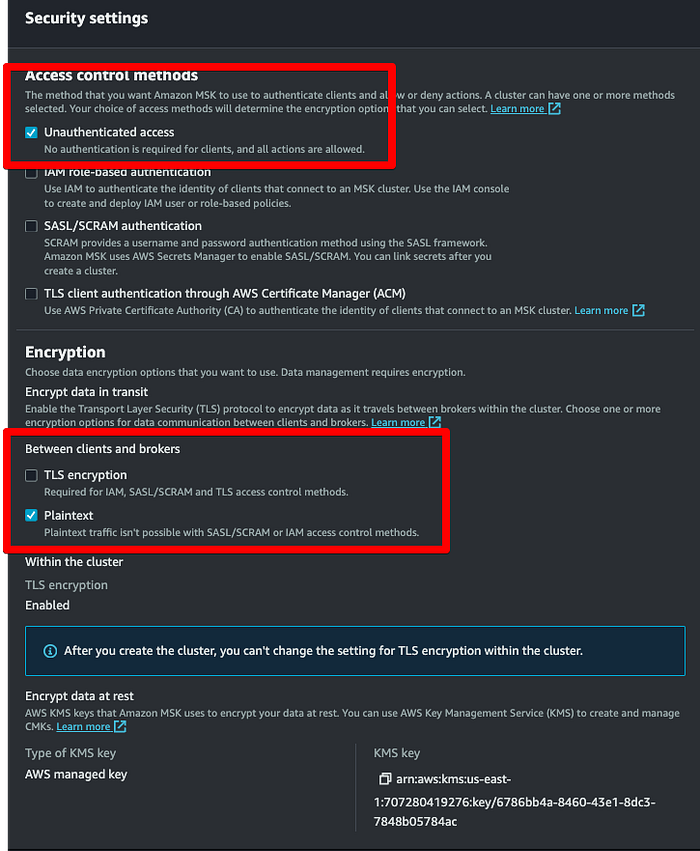
In the security settings, make sure these two red highlighted checkboxes are the only ones that are selected. The reason those 2 options are selected is because if we need encryption we will need to create encryption certificates at producer and consumer level which is not in scope of this blog post.
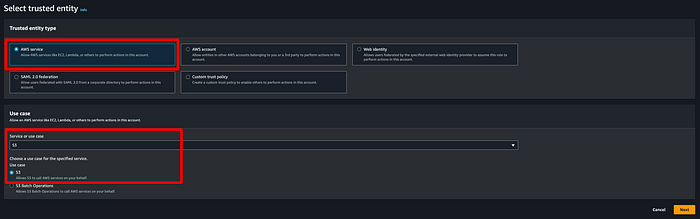
Step 3: Create an IAM role for MSK connector that can write to the destination bucket
Next, we need a role that MSK can use to write topic data to our destination bucket. Go to the IAM console, click on Roles > Create Roles and select the options below. I created a role by the name “msk-blog-role”.
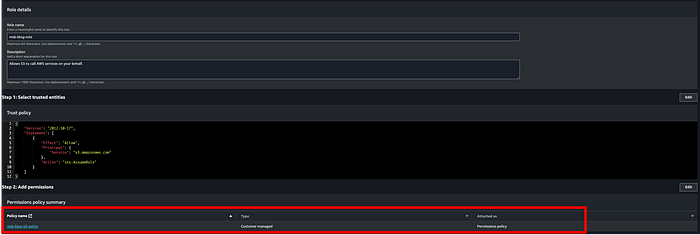
Create a custom policy for your MSK IAM role to enable it to access your S3 bucket intended for use with the production cluster. Below is the JSON for the IAM policy that you will attach to the IAM role. I named my policy “msk-blog-s3-policy”:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListAllMyBuckets"
],
"Resource": "arn:aws:s3:::*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:DeleteObject"
],
"Resource": "arn:aws:s3:::<name-of-your-bucket>"
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts",
"s3:ListBucketMultipartUploads"
],
"Resource": "*"
}
]
}Once the policy is created, attach it to your role:
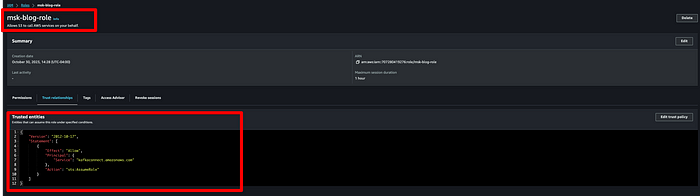
Once the policy is attached, save the role, then click on “Trust relationships” and replace it with the JSON below:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "kafkaconnect.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
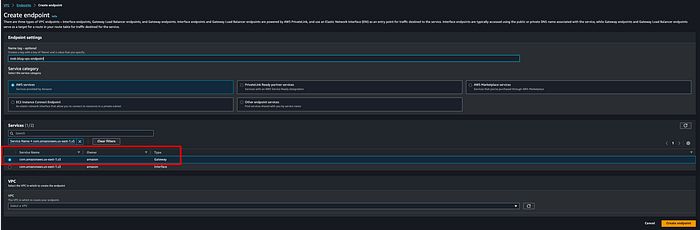
Step 4: Create an Amazon VPC endpoint from the MSK cluster VPC to Amazon S3
You will need a VPC endpoint in order for the MSK connector to write data to the destination S3 bucket without traversing the open internet. I created gateway endpoint msk-blog-vpc-endpoint:
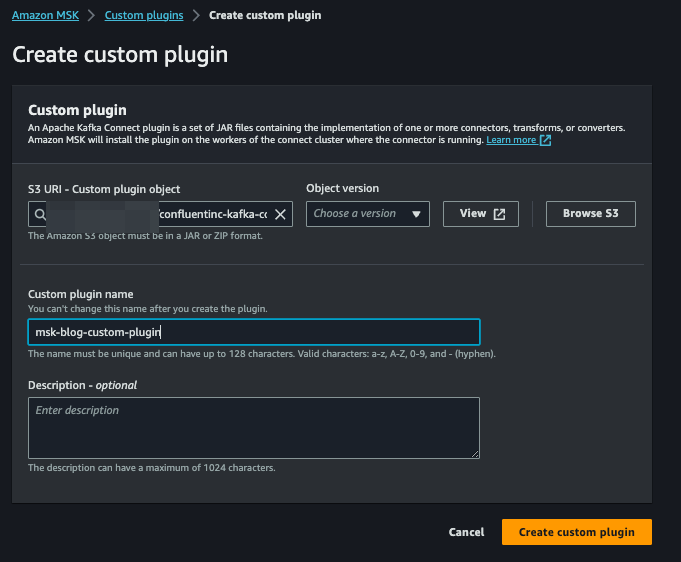
Step 5: Create a custom plugin for AWS MSK connector using Confluent S3 Sink Connector
Download Confluent S3 Sink Connector [LINK] and upload it to an S3 bucket. Next, navigate to the AWS MSK console and click on “Custom plugins” on the left hand side and click on “Create custom plugin”. Select the zip file by browsing to the S3 bucket where you uploaded the Confluent S3 Sink Connector zip file, name the plugin,and click on “Create custom plugin”:
Step 6: Create a client machine and Apache Kafka topic for testing.
Launch an Amazon Linux 2 AMI EC2 instance. Next, enable this newly created EC2 instance to send data to the MSK cluster by adding the security group associated with the MSK cluster to inbound rules of the newly created EC2 instance for All Traffic, as shown below:

To create a Kafka topic, run the following command on the EC2 instance:
#Install Java
sudo yum install java-1.8.0
#Download Apache Kafka
wget https://archive.apache.org/dist/kafka/2.2.1/kafka_2.12-2.2.1.tgz
#Unzip the file
tar -xzf kafka_2.12-2.2.1.tgz
Next, get the client information for an Apache ZooKeeper connection. Shown below is where to find this for your MSK cluster.
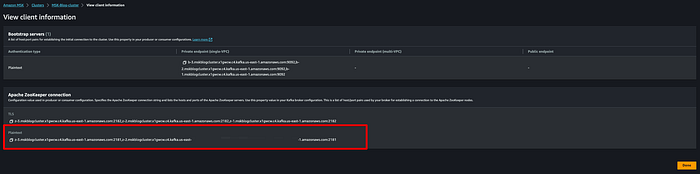
Use that plain text connection string when running the following command:
#Sample Command
<path-to-your-kafka-installation>/bin/kafka-topics.sh --create --bootstrap-server bootstrapServerString --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
#Actual Command will look like below.
/home/ec2-user/kafka_2.12-2.2.1/bin/kafka-topics.sh --create --bootstrap-server z-3.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-2.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-1.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181 --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
Step 7: Create the MSK connector
Create an MSK connector using the custom Confluent plugin we created before:
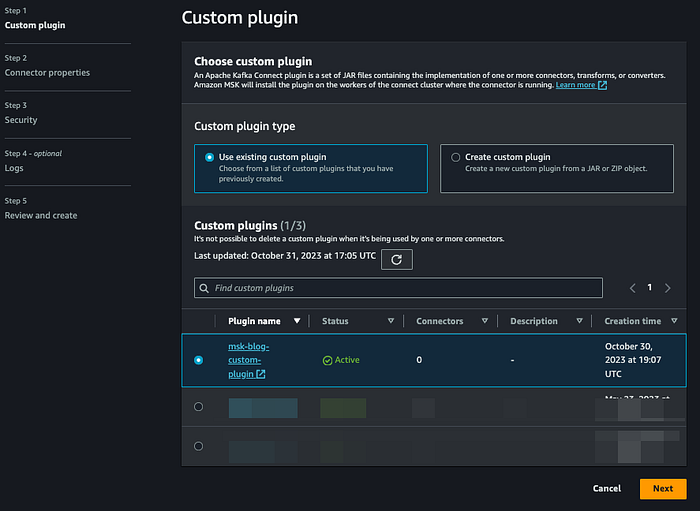
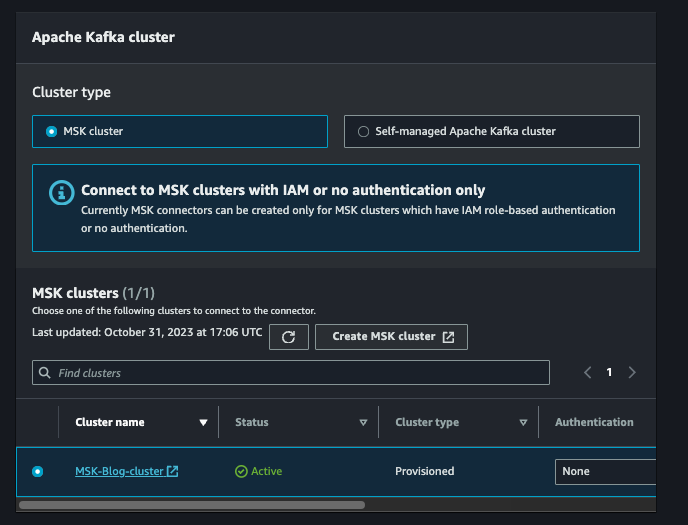
Click on next then name the connector as per your convention. Select your MSK cluster.
In the connector configuration field, add the code snippet below. Don’t forget to replace the S3 bucket with your actual destination bucket name.
connector.class=io.confluent.connect.s3.S3SinkConnector
s3.region=us-east-1
format.class=io.confluent.connect.s3.format.json.JsonFormat
flush.size=1
schema.compatibility=NONE
tasks.max=2
topics.regex=name.(.*)
partitioner.class=io.confluent.connect.storage.partitioner.DefaultPartitioner
storage.class=io.confluent.connect.s3.storage.S3Storage
s3.bucket.name=<my-destination-bucket>
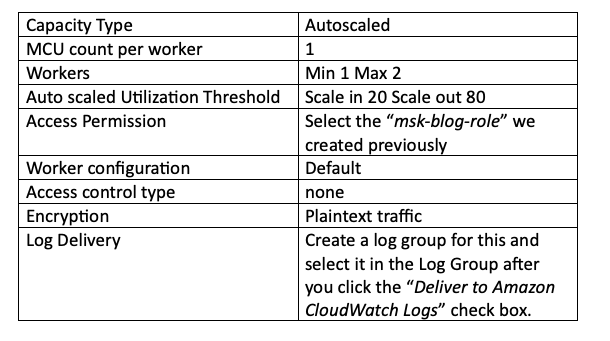
topics.dir=tutorialThe remaining configurations you will need are listed below. I am keeping capacity and workers the default as this is a POC but you need to adjust the capacity based on the number of topics your MSK cluster is handling.
Finally, click “Create connector”. If all your settings are correctly set as shown above you will see green “Running” text in the status field for your connector. If it shows “Failed” then you have likely missed a step or made a mistake in the steps above. You can check the creation logs in the log group you created for this connector in Cloud Watch logs to help determine what went wrong:

To test if the Connector integration is working, let’s create test messages in the EC2 server for our producer.
Run the command below on the producer EC2 server:
/home/ec2-user/kafka_2.12-2.2.1/bin/kafka-console-producer.sh --broker-list z-3.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-2.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-1.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181 --replication-factor 2 --partitions 1 --topic mkc-tutorial-topicEnter any message you want at the EC2 command line. Wait for a minute or two, then check the destination bucket to see if the message was backed up in the bucket:
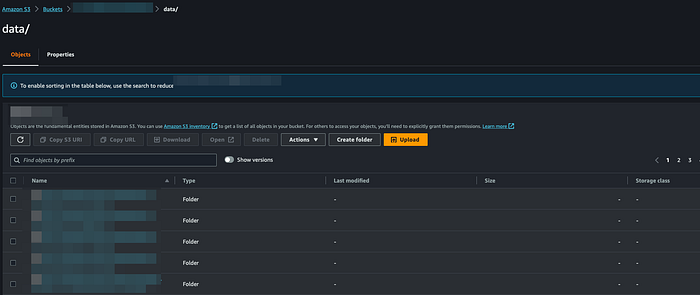
Now your topic data is being backed up to the destination bucket we created. However, during an AWS region outages, that data will be not accessible, and thus you need to make sure that you have set up data replication for the destination production bucket (e.g. us-east-1) to the bucket in your DR region (us-west-2) by following the AWS documentation linked here.
References:
[1] https://aws.amazon.com/msk/
[2] https://docs.aws.amazon.com/msk/latest/developerguide/msk-connect.html
[3] https://docs.aws.amazon.com/msk/latest/developerguide/msk-connect-getting-started.html

